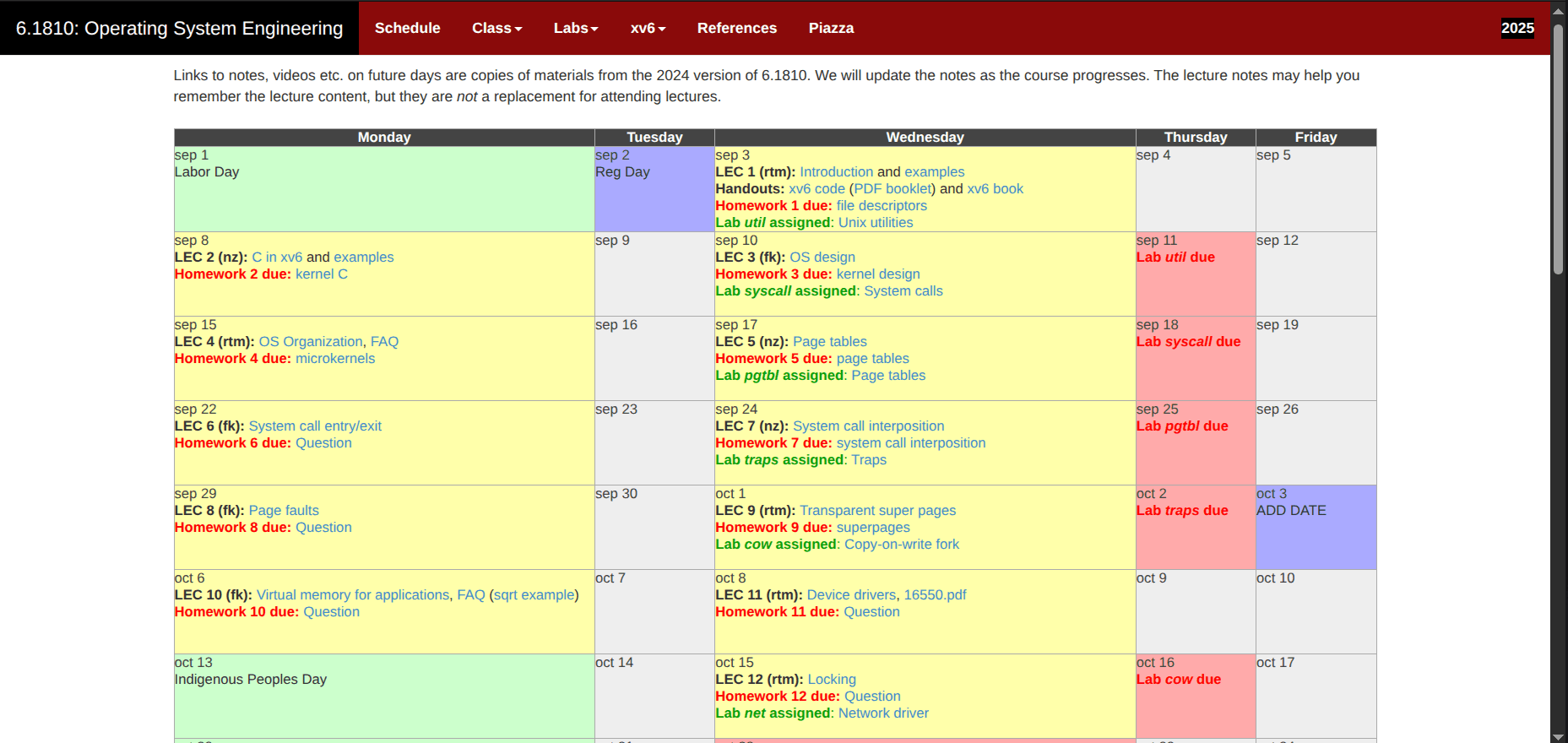
OS Design and Implementation: (Week 8-9) - Scheduling; File system
MIT 6.1810 Fall2025 Course - Week 8-9: Scheduling; File system
Software Developer | Love Low Level Eng. | Python, Javascript, C, Linux I'm learning backend development and system programming.
Scheduling: big points
To execute multiple processes (multiplexing), xv6 switches each CPU from one process to another in the following situations:
Voluntary switches: Occur when a trap (such as a system call or timer interrupt) happens during the execution of a process.
Involuntary switches: Occur when xv6 forces the CPU to switch if a process takes too long to execute.
However, this approach presents several challenges (as noted in the xv6 book):
How to switch from one process to another
Forcing switches that are transparent to the user
Managing situations when multiple CPUs attempt to switch and run the same process simultaneously
Handling memory, I/O, and other resources
Keeping track of which process is running on each CPU during switches
File system
A file system is a method for an OS to organize and access data on a disk, whether it's a hard disk drive or a solid-state drive. It serves as a hierarchy that enables indirect data access, allowing the OS to perform actions and checks before and after saving or reading data. In xv6 and Unix-like operating systems, this structure is implemented in a specific order.
File descriptor: small integer representing a kernel-managed object that a process will use to read from/write to a file.
Pathname
Directory
Inode: Data structure that holds info (size, permissions, file type, pointer to the block adresses, ...)
Logging: For crash recovery, this layer allows the OS to store descriptions of write operations before execution, enabling replay or discarding if a crash occurs.
Buffer Cache: LRU data structure that cached and ensure the accessed block of data
Disk (block/sector): unit of stockage of data
Remember that the filesystem treats the disk as a large, continuous array of blocks segmented to store data. There's much more to learn about filesystems, but for now, I'll stick to the fundamentals.
Labs
There are two labs in the chapter and I completed the first one
Large files (completed): modifies the xv6 file system to support much larger files by adding a doubly-indirect block to inodes, increasing the file limit from 268 blocks to 65,803 blocks. You must update functions like
bmap()anditrunc()to correctly allocate, map, and free direct, indirect, and doubly-indirect blocks while preserving the inode size. (Figure 1 below)Symbolic links: This assignment adds symbolic link support to xv6 by implementing the
symlink(target, path)system call, which creates links that reference files by pathname instead of inode. You must introduce a new symbolic link file type, store target paths in link inodes, and modifyopen()to recursively resolve symbolic links unless theO_NOFOLLOWflag is used, while also detecting cycles to avoid infinite loops.

Figure 1: Lab FS - Large Files
Next week
Next weeks is about... no there is no "next week".
The upcoming chapters primarily focus on reading papers on specific topics such as virtual machines and eBPF.. For now, let's say I'm nearing the end of the course.
By the way, here's my GitHub repo for the lab course: https://github.com/TawalMc/MIT-6.1810Fall2025-xv6